Apache Spark and Big Data
Apache Spark is an open-source distributed data processing and analytics framework designed for Big Data applications.
It provides a fast and general-purpose data processing engine that can handle large-scale data processing tasks efficiently.
Spark is developed by the Apache Software Foundation and has gained widespread popularity due to its ease of use, speed, and versatility.
Key features of Apache Spark:
-
In-Memory Processing: Spark performs most data processing operations in-memory, reducing the need for frequent data read/write operations to disk and significantly improving processing speed.
-
Fault Tolerance: Spark offers fault tolerance through lineage information, which allows it to recompute lost data in case of node failures.
-
Data Abstraction: Spark provides high-level APIs in Scala, Java, Python, and R, making it accessible to developers with different language preferences.
-
Unified Data Processing: Spark supports various data processing tasks, including batch processing, interactive queries (SQL), real-time streaming, and machine learning.
-
Resilient Distributed Datasets (RDDs): Spark's core data structure is RDD, a fault-tolerant collection of data that can be processed in parallel across a cluster.
-
Spark SQL: Spark SQL provides a module for querying structured data using SQL, enabling seamless integration with existing SQL-based tools and systems.
-
Spark Streaming: Spark Streaming allows real-time data processing and analytics by ingesting and processing data streams in mini-batches.
-
Machine Learning Library (MLlib): Spark's MLlib offers a scalable and distributed machine learning library for building and deploying machine learning models.
-
Graph Processing (GraphX): Spark's GraphX library provides tools for graph processing and analytics, suitable for social network analysis and other graph-based computations.
-
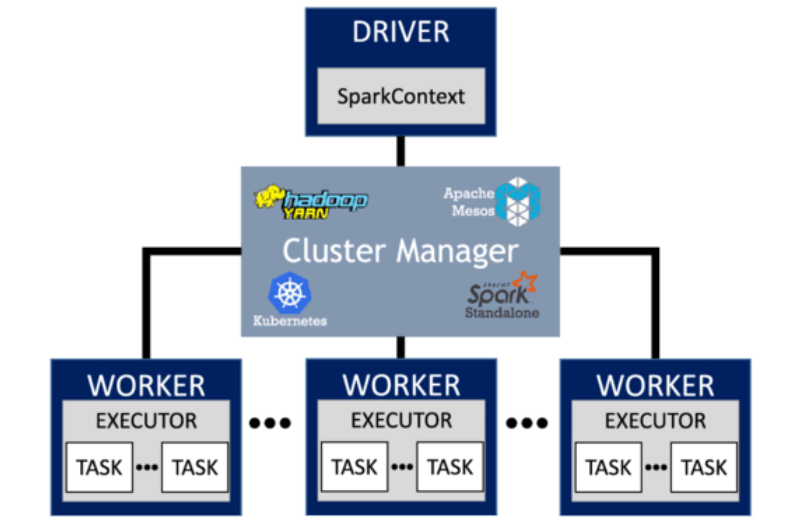
Cluster Manager Integration: Spark can run on various cluster managers, such as Apache Hadoop YARN, Apache Mesos, and Kubernetes, allowing users to integrate it into existing infrastructure easily.
Apache Spark is an open-source unified analytics engine for large-scale data processing.
Spark provides high-level APIs in Java, Scala, Python, and R, and an optimized engine that supports general execution graphs for data analysis.
It also supports a rich set of higher-level tools including Spark SQL for SQL and DataFrames, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for incremental computation and stream processing.
Spark is designed to be fast and scalable. It can process data up to 100x faster than Hadoop MapReduce on certain workloads. Spark is also very scalable, and can be run on a cluster of thousands of nodes.
Spark is a good choice for a wide range of big data applications, including:
- Batch processing: Spark can be used to process large datasets in batches.
- Real-time processing: Spark can be used to process streaming data in real time.
- Machine learning: Spark can be used to train and deploy machine learning models.
- Graph processing: Spark can be used to process graph data.
- SQL: Spark can be used to run SQL queries on large datasets.
Spark is a powerful and versatile tool that can be used for a wide range of big data applications. If you are looking for a tool to process large datasets, then Spark is a good choice.
Benefits of using Apache Spark:
- Speed: Spark is much faster than Hadoop MapReduce for certain workloads.
- Scalability: Spark can be scaled to handle very large datasets.
- Ease of use: Spark is easy to use, even for beginners.
- Flexibility: Spark can be used for a wide range of big data applications.
- Community: Spark has a large and active community of users and developers.
If you are looking for a tool to process large datasets, then Apache Spark is a good choice. It is a powerful and versatile tool that is easy to use and has a large and active community.
Limitations of Apache Spark:
- Memory requirements: Spark can be memory-intensive, so it is important to have enough memory available.
- Complexity: Spark can be complex to set up and use, especially for complex applications.
- Dependencies: Spark depends on a number of other libraries, so it can be difficult to install and manage.
Apache Spark is known for its performance gains compared to traditional MapReduce-based processing frameworks like Hadoop MapReduce.
It achieves this by optimizing task execution and minimizing data shuffling between nodes.
Spark's rich set of libraries and APIs make it a powerful choice for data engineers, data scientists, and developers working with Big Data applications and analytics.
Its flexibility and support for various data sources, coupled with its ability to handle both batch and real-time data processing, make it a versatile tool in the Big Data ecosystem.
Enroll Now
- Database Management System
- SQL