Big Data and Hadoop
Big Data and Hadoop are two related concepts that address the challenges of processing and analyzing massive volumes of data.
Hadoop is an open-source distributed computing framework designed to store, process, and analyze large datasets, while Big Data refers to the vast amount of data generated from various sources.
- Big Data: Big Data refers to datasets that are too large, complex, and diverse to be effectively processed using traditional data management and processing methods. These datasets typically exceed the processing capabilities of conventional databases and require specialized tools and technologies for storage and analysis.
Big Data is characterized by the "3Vs":
- Volume: The sheer size of data, often in petabytes or even exabytes.
- Velocity: The speed at which data is generated and needs to be processed in real-time or near real-time.
- Variety: The diversity of data types, including structured, semi-structured, and unstructured data.
Examples of Big Data sources include social media interactions, sensor data, website logs, machine-generated data, and multimedia content.
- Hadoop: Hadoop is an open-source framework developed by the Apache Software Foundation to handle Big Data processing and storage. It provides a distributed file system called Hadoop Distributed File System (HDFS) and a processing engine called MapReduce.
Key components of Hadoop include:
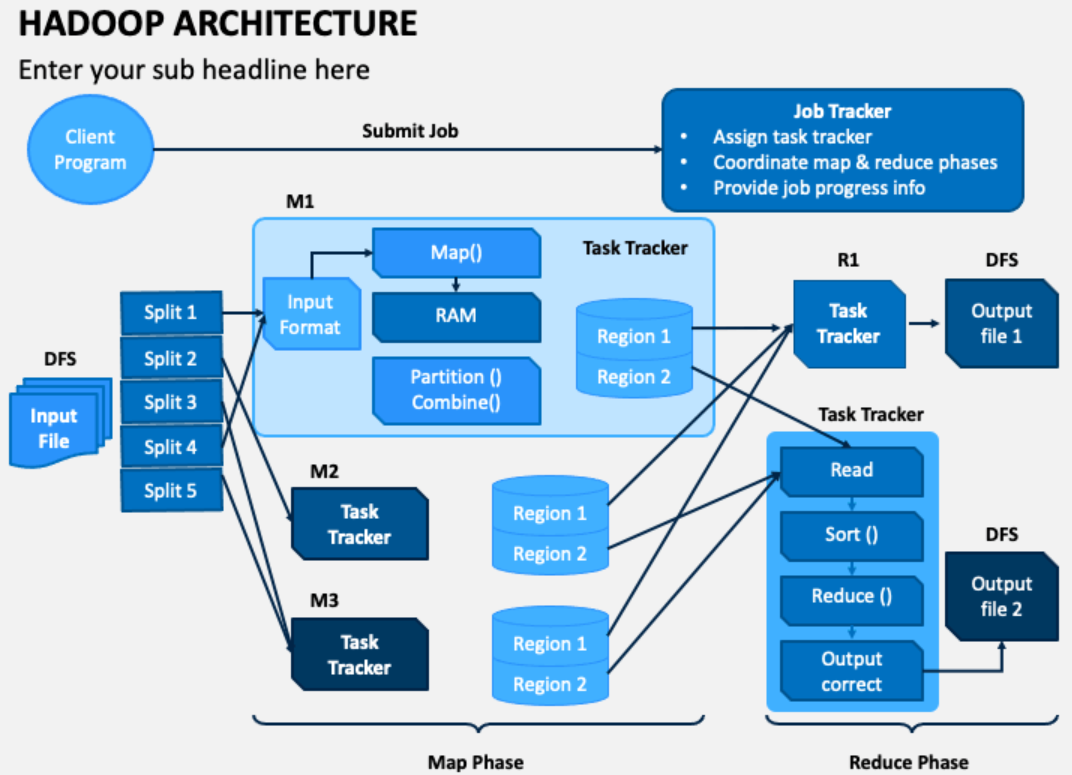
- HDFS: Hadoop Distributed File System is a distributed file system that can store large datasets across multiple servers. It provides fault tolerance and high throughput data access.
- MapReduce: A programming model used to process and analyze data in parallel across a Hadoop cluster. It breaks down complex tasks into smaller, manageable sub-tasks and processes them in parallel on different nodes.
Hadoop is an open-source software framework that is used to store and process large datasets.
It is a distributed system that can run on a cluster of commodity hardware.
Hadoop is a popular choice for big data applications because it is scalable, reliable, and fault-tolerant.
Hadoop consists of four main modules:
- Hadoop Distributed File System (HDFS): HDFS is a distributed file system that stores data on a cluster of nodes. HDFS is designed to be fault-tolerant and scalable.
- MapReduce: MapReduce is a programming model that is used to process large datasets. MapReduce is a divide-and-conquer approach to processing data.
- YARN: YARN is a resource management framework that is used to manage the resources in a Hadoop cluster. YARN can be used to run MapReduce jobs, as well as other types of jobs.
- Hive: Hive is a SQL-like language that is used to query data in Hadoop. Hive is a good choice for users who are familiar with SQL.
Hadoop has become a popular choice for Big Data processing due to its scalability, fault-tolerance, and cost-effectiveness.
It allows organizations to store and process massive amounts of data on commodity hardware clusters, making it more accessible and affordable.
However, as technology has evolved, other Big Data processing frameworks and tools have emerged, such as Apache Spark, which provides faster data processing and additional capabilities like in-memory computing and machine learning support.
As a result, the Big Data landscape has become more diverse, with various tools and technologies to address different use cases and requirements.
Enroll Now
- Database Management System
- SQL