YOLO (You Only Look Once) algorithm
YOLO (You Only Look Once) is a popular and influential real-time object detection algorithm in computer vision. YOLO's key innovation is its ability to perform object detection in a single pass through the neural network, making it extremely efficient and well-suited for real-time applications. Instead of dividing the image into a grid of regions, YOLO predicts bounding boxes and class probabilities directly from the entire image.
How YOLO works:
-
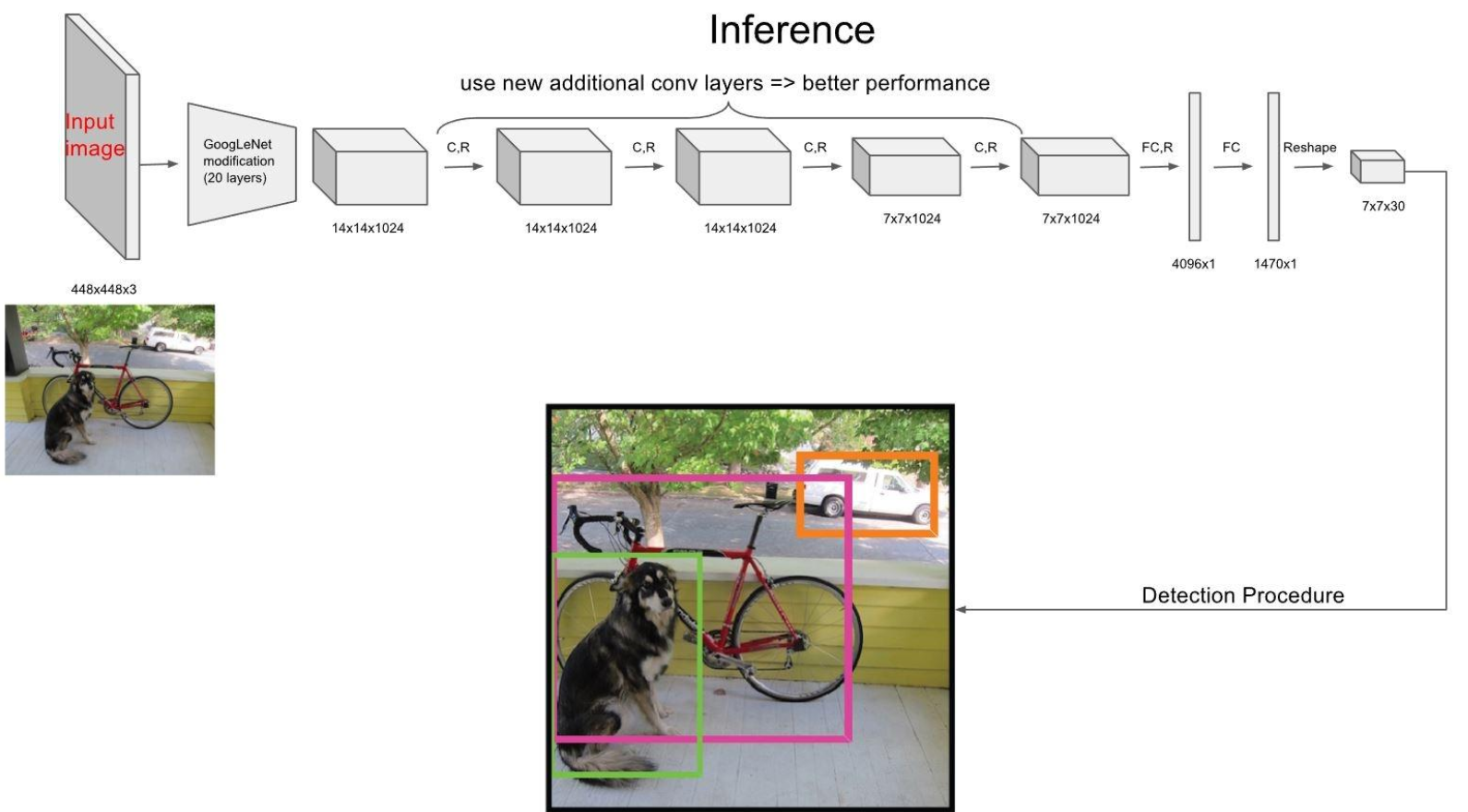
Grid and Anchor Boxes: YOLO divides the input image into a grid of cells. Each cell is responsible for predicting objects that fall within its boundaries. Additionally, YOLO uses anchor boxes, which are pre-defined bounding box shapes of different sizes and aspect ratios. These anchor boxes are used to predict the dimensions of the bounding boxes.
-
Predictions: For each cell in the grid, YOLO predicts bounding boxes and class probabilities. Each bounding box consists of four coordinates (x, y, width, height) representing the center of the box and its dimensions. Class probabilities are estimated for each object class the model is trained on.
-
Confidence Score: YOLO also predicts a confidence score for each bounding box, indicating how likely the box contains an object and how accurate the predicted bounding box is.
-
Non-Maximum Suppression (NMS): After predictions are made, YOLO uses non-maximum suppression to eliminate duplicate detections. Boxes with a confidence score below a certain threshold are discarded. For the remaining boxes, NMS suppresses boxes with high overlap, keeping only the most confident ones.
-
Output: The final output of YOLO is a list of bounding boxes, each associated with a class label and a confidence score.
-
Loss Function: YOLO uses a combination of classification loss (cross-entropy) and localization loss (mean squared error) to train the network. The loss function encourages the model to accurately predict both the class probabilities and the bounding box coordinates.
YOLO comes in several versions, including YOLOv1, YOLOv2 (also known as YOLO9000 or YOLO9000v2), YOLOv3, and more. Each version introduces improvements and optimizations to the original YOLO concept. YOLOv3, for example, uses a feature pyramid network and predicts bounding boxes at multiple scales to handle objects of different sizes.
The advantages of YOLO include its speed and efficiency, making it suitable for real-time applications like video surveillance, robotics, and autonomous vehicles. However, it might struggle with small objects or objects close together due to the limitations of its grid-based approach. Despite its limitations, YOLO has had a significant impact on the field of object detection and continues to be an influential algorithm.
Enroll Now
- Python Programming
- Machine Learning