Image classification
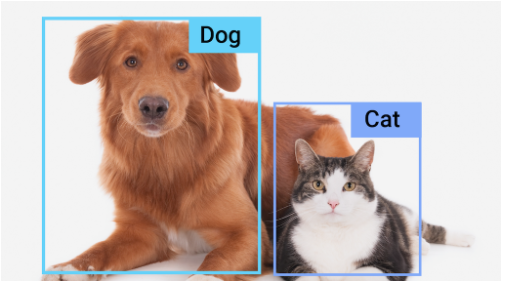
Image classification is a fundamental task in the field of computer vision that involves categorizing an input image into one of several predefined classes or categories.
The goal is to teach a machine learning model to recognize and distinguish different objects or patterns within images.
This task has a wide range of applications, including facial recognition, object detection, medical image analysis, autonomous vehicles, and more.
Overview of the process involved in image classification:
-
Dataset Collection and Preparation: Gather a labeled dataset containing images along with corresponding class labels. The dataset should be diverse and representative of the real-world scenarios you want the model to handle. Common datasets include CIFAR-10, CIFAR-100, ImageNet, and MNIST.
-
Data Preprocessing: Prepare the images for training by resizing them to a consistent size, normalizing pixel values, and augmenting the data if necessary (using techniques like rotation, cropping, flipping, etc.). Data augmentation helps improve the model's generalization ability.
-
Model Selection: Choose an appropriate model architecture for image classification. Convolutional Neural Networks (CNNs) are the most commonly used architecture for this task due to their ability to capture spatial hierarchies and patterns within images.
-
Model Design and Training: Design the layers and structure of the CNN. This typically includes convolutional layers, pooling layers, fully connected layers, and an output layer with the number of units corresponding to the number of classes. Initialize the model's weights and biases, and then train the model on the prepared dataset using optimization techniques like stochastic gradient descent (SGD) or more advanced optimizers like Adam.
-
Loss Function: Choose an appropriate loss function for training the model. For multi-class classification, commonly used loss functions include categorical cross-entropy and softmax loss.
-
Model Evaluation: After training, evaluate the model's performance on a separate validation or test dataset that it has never seen before. Metrics such as accuracy, precision, recall, F1 score, and confusion matrices are used to assess the model's performance.
-
Fine-Tuning and Optimization: Depending on the evaluation results, you might need to fine-tune hyperparameters, adjust the model architecture, or use techniques like transfer learning, where a pre-trained model (such as a model trained on ImageNet) is adapted to your specific task.
-
Deployment: Once you are satisfied with the model's performance, deploy it to your desired application. This could involve integrating the model into a web application, mobile app, or any other platform where you want to perform real-time image classification.
Remember that the success of image classification relies not only on the model architecture but also on the quality and size of the dataset, proper preprocessing, careful selection of hyperparameters, and iterative optimization.
Image classification is a computer vision task of assigning a label to an image from a predefined set of categories.
The categories can be anything, such as objects, scenes, or activities.
The goal of image classification is to build a model that can accurately predict the label of an image.
There are two main types of image classification:
supervised and unsupervised.
- Supervised image classification is the most common type of image classification. In supervised learning, the model is trained on a set of images that have already been labeled. The model learns to associate the features of the images with the labels.
- Unsupervised image classification is a more challenging task. In unsupervised learning, the model is not given any labeled images. The model must learn to cluster the images into groups based on their similarities.
Image classification is a powerful tool that can be used in a variety of applications, such as:
- Object detection: Identifying objects in an image, such as cars, people, or animals.
- Scene recognition: Identifying the type of scene in an image, such as a beach, a forest, or a city.
- Activity recognition: Identifying the activity that is taking place in an image, such as a person walking, running, or driving.
- Medical image analysis: Identifying diseases or abnormalities in medical images, such as X-rays or MRI scans.
- Self-driving cars: Identifying objects and scenes on the road to help the car navigate safely.
Image classification is a rapidly evolving field, and new research is being published all the time. As the technology continues to improve, image classification will become even more powerful and widespread.
Some of the most common techniques used for image classification:
- Support vector machines (SVMs): SVMs are a type of supervised learning algorithm that can be used for classification and regression tasks. They work by finding the hyperplane that best separates the data points in the training set.
- Decision trees: Decision trees are a type of supervised learning algorithm that can be used for classification and regression tasks. They work by building a tree-like structure that represents the decision rules for classifying the data points.
- Random forests: Random forests are a type of ensemble learning algorithm that combines multiple decision trees to improve the accuracy of the predictions.
- Convolutional neural networks (CNNs): CNNs are a type of deep learning algorithm that are specifically designed for image classification tasks. They work by learning the features of images in a hierarchical manner.
Enroll Now
- Python Programming
- Machine Learning