Convolutional Neural Network (CNN)
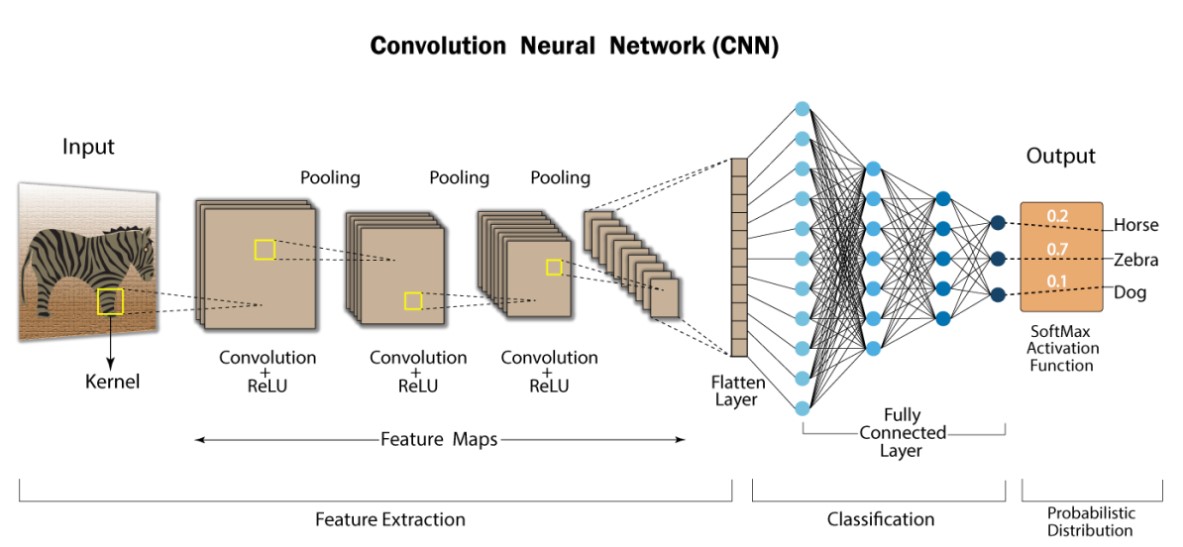
A Convolutional Neural Network (CNN) is a specialized type of artificial neural network designed for processing structured grid data, most notably for tasks related to computer vision, such as image and video analysis. CNNs are particularly effective at capturing patterns, features, and hierarchies of information in images.They have played a pivotal role in advancing the field of deep learning and have achieved remarkable results in various computer vision tasks.
Core Components of CNNs
CNNs consist of several types of layers that work together to extract features from input data:
a. Convolutional Layers
- Convolution Operation: The fundamental building block of a CNN, where a small filter (or kernel) slides over the input data to produce feature maps. This operation helps in capturing spatial relationships in the data.
- Filters/Kernels: Learnable parameters that are trained to detect specific features, such as edges, textures, or patterns.
- Stride: The step size with which the filter moves across the input. Larger strides reduce the spatial dimensions more aggressively.
- Padding: Adds extra pixels around the input data to control the spatial size of the output. Common types are 'valid' (no padding) and 'same' (padding to maintain output size).
b. Pooling Layers
- Max Pooling: Reduces the spatial dimensions of the input by taking the maximum value in each patch of the feature map. It helps in downsampling and reducing computational load.
- Average Pooling: Similar to max pooling but takes the average value instead. Less commonly used but can be useful in certain scenarios.
- Purpose: Pooling layers help to reduce the dimensionality of the feature maps, making the network more computationally efficient and focusing on the most important features.
c. Fully Connected Layers
- Dense Layers: Standard neural network layers where each neuron is connected to every neuron in the previous layer. These layers are typically used at the end of the CNN for classification tasks.
- Flattening: Converts the 2D matrix of the feature maps into a 1D vector, which can be fed into the fully connected layers.
Activation Functions
Activation functions introduce non-linearity into the network, enabling it to learn complex patterns:
- ReLU (Rectified Linear Unit): Outputs the input directly if positive, otherwise zero. It is the most commonly used activation function in CNNs.
- Leaky ReLU: A variation of ReLU that allows a small gradient when the input is negative, helping to avoid dying neurons.
Architecture
A typical CNN architecture consists of a series of convolutional and pooling layers followed by one or more fully connected layers. An example architecture might look like this:
- Input Layer: Takes in the raw pixel values of the image.
- Convolutional Layer: Applies multiple filters to extract different features.
- Activation Function: Applies non-linearity (e.g., ReLU).
- Pooling Layer: Reduces spatial dimensions.
- Additional Convolutional and Pooling Layers: Repeat the process to learn higher-level features.
- Flattening Layer: Converts the 2D data to 1D.
- Fully Connected Layers: Perform the final classification.
Training CNNs
The training process for CNNs involves:
- Forward Propagation: Input data is passed through the network to generate predictions.
- Loss Calculation: The difference between the predicted and actual values is computed using a loss function (e.g., cross-entropy for classification).
- Backpropagation: The gradients of the loss with respect to each weight are calculated and used to update the weights, minimizing the loss over time.
- Optimization Algorithms: Techniques like Stochastic Gradient Descent (SGD) and Adam are used to adjust the weights based on the calculated gradients.
Applications of CNNs
- Image Classification: Assigning a label to an entire image (e.g., cat, dog).
- Object Detection: Identifying and localizing objects within an image (e.g., bounding boxes around cars).
- Semantic Segmentation: Classifying each pixel in an image into predefined categories (e.g., segmenting different objects in a scene).
- Image Generation: Creating new images from learned patterns (e.g., GANs).
Popular CNN Architectures
Several well-known CNN architectures have been developed and widely used:
- LeNet-5: One of the earliest CNNs, used for digit recognition.
- AlexNet: Won the 2012 ImageNet competition, significantly deeper than LeNet-5.
- VGGNet: Known for its simplicity and use of very small (3x3) convolution filters.
- GoogLeNet/Inception: Introduced the concept of inception modules to capture multi-scale features.
- ResNet (Residual Networks): Introduced residual blocks to allow very deep networks without the vanishing gradient problem.
Challenges and Considerations
- Computational Resources: Training deep CNNs requires significant computational power and memory, often necessitating the use of GPUs.
- Overfitting: When the model performs well on training data but poorly on unseen data. Techniques like dropout, data augmentation, and regularization help mitigate this.
- Hyperparameter Tuning: Choosing the right architecture, number of layers, filter sizes, and other hyperparameters is crucial and often requires experimentation.
CNNs have revolutionized computer vision and continue to be a powerful tool for various image-related tasks. Their ability to automatically and effectively learn hierarchical representations of data makes them indispensable in modern deep learning applications.
Enroll Now
- Python Programming
- Machine Learning