Activation functions
Activation functions are crucial components in deep learning and artificial neural networks. They introduce non-linearity to the network, allowing it to model complex relationships and learn intricate patterns in data. Each neuron (node) in a neural network applies an activation function to the weighted sum of its inputs, producing an output signal.
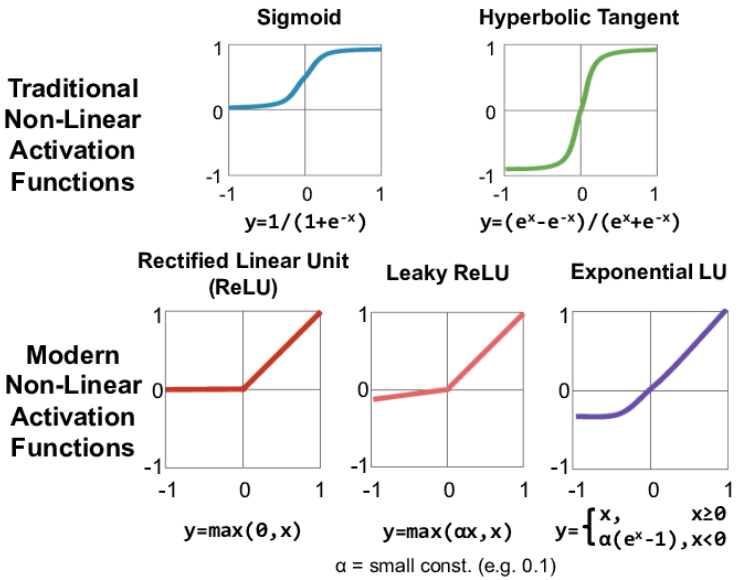
common activation functions used in deep learning:
Sigmoid Function
- Equation:

- Range: 0 to 1
- Usage: Primarily used in the output layer for binary classification problems.
- Advantages: Smooth gradient, outputs values between 0 and 1, interpreted as probabilities.
- Disadvantages: Prone to vanishing gradient problem, slow convergence.
Hyperbolic Tangent (Tanh) Function
- Equation:

- Range: -1 to 1
- Usage: Often used in hidden layers of neural networks.
- Advantages: Zero-centered outputs, which can make optimization easier.
- Disadvantages: Still suffers from the vanishing gradient problem, though less severely than the sigmoid function.
Rectified Linear Unit (ReLU)
- Equation:

- Range: 0 to ∞
- Usage: Widely used in hidden layers of neural networks.
- Advantages: Computationally efficient, mitigates vanishing gradient problem, promotes sparsity in the network.
- Disadvantages: Can suffer from the "dying ReLU" problem, where neurons can become inactive and only output zero.
Leaky ReLU
- Equation:
 where α\alphaα is a small constant (e.g., 0.01)
where α\alphaα is a small constant (e.g., 0.01) - Range: −∞ to ∞
- Usage: Used to address the dying ReLU problem.
- Advantages: Allows a small, non-zero gradient when the unit is not active.
- Disadvantages: The selection of the α\alphaα parameter is crucial and can affect performance.
Parametric ReLU (PReLU)
- Equation:
 where α\alphaα is a learned parameter
where α\alphaα is a learned parameter - Range: −∞ to ∞
- Usage: Similar to Leaky ReLU but with α\alphaα learned during training.
- Advantages: The parameter α\alphaα is learned from the data, potentially improving performance.
- Disadvantages: Adds additional parameters to be learned, increasing the complexity of the model.
Exponential Linear Unit (ELU)
- Equation:

- Range: −α to ∞
- Usage: Used in hidden layers to improve learning characteristics.
- Advantages: Helps mitigate the vanishing gradient problem, improves learning speed and accuracy.
- Disadvantages: Computationally more expensive than ReLU.
Swish
- Equation:

- Range: −∞ to ∞
- Usage: Developed by Google and used in some state-of-the-art models.
- Advantages: Smooth and non-monotonic, leading to better performance in some cases.
- Disadvantages: More computationally expensive than ReLU.
Softmax
- Equation:

- Range: 0 to 1 (sums to 1 across output nodes)
- Usage: Used in the output layer for multi-class classification problems.
- Advantages: Outputs can be interpreted as probabilities.
- Disadvantages: Computationally intensive for large output spaces, can be sensitive to outliers in the input data.
GELU (Gaussian Error Linear Unit)
- Equation:
 is the cumulative distribution function of the standard normal distribution.
is the cumulative distribution function of the standard normal distribution. - Range: −∞ to ∞
- Usage: Used in models like BERT and other NLP architectures.
- Advantages: Smooth, combines properties of ReLU and sigmoid/tanh, and empirically shows good performance in many tasks.
- Disadvantages: More complex to compute compared to ReLU.
Choosing an Activation Function
The choice of activation function can significantly affect the performance and training of a neural network. Here are some guidelines:
- ReLU and its variants (Leaky ReLU, PReLU) are often the default choice for hidden layers due to their simplicity and effectiveness.
- Sigmoid and Tanh are less common for hidden layers in deep networks due to vanishing gradient issues but can be useful in specific architectures or applications.
- Softmax is typically used in the output layer for multi-class classification.
- ELU, Swish, and GELU can be explored for potentially better performance in certain tasks but come with increased computational costs.
Activation functions play a critical role in the success of deep learning models by enabling them to learn and represent complex patterns in data. The choice of activation function should be made based on the specific requirements and characteristics of the task at hand.
Enroll Now
- Python Programming
- Machine Learning