Encoder Decoder Architecture
In natural language processing (NLP), an encoder-decoder architecture is a widely used framework for various tasks, including machine translation, text summarization, and sequence-to-sequence tasks. The encoder-decoder model consists of two main components: the encoder and the decoder. These components work together to transform input sequences into output sequences.
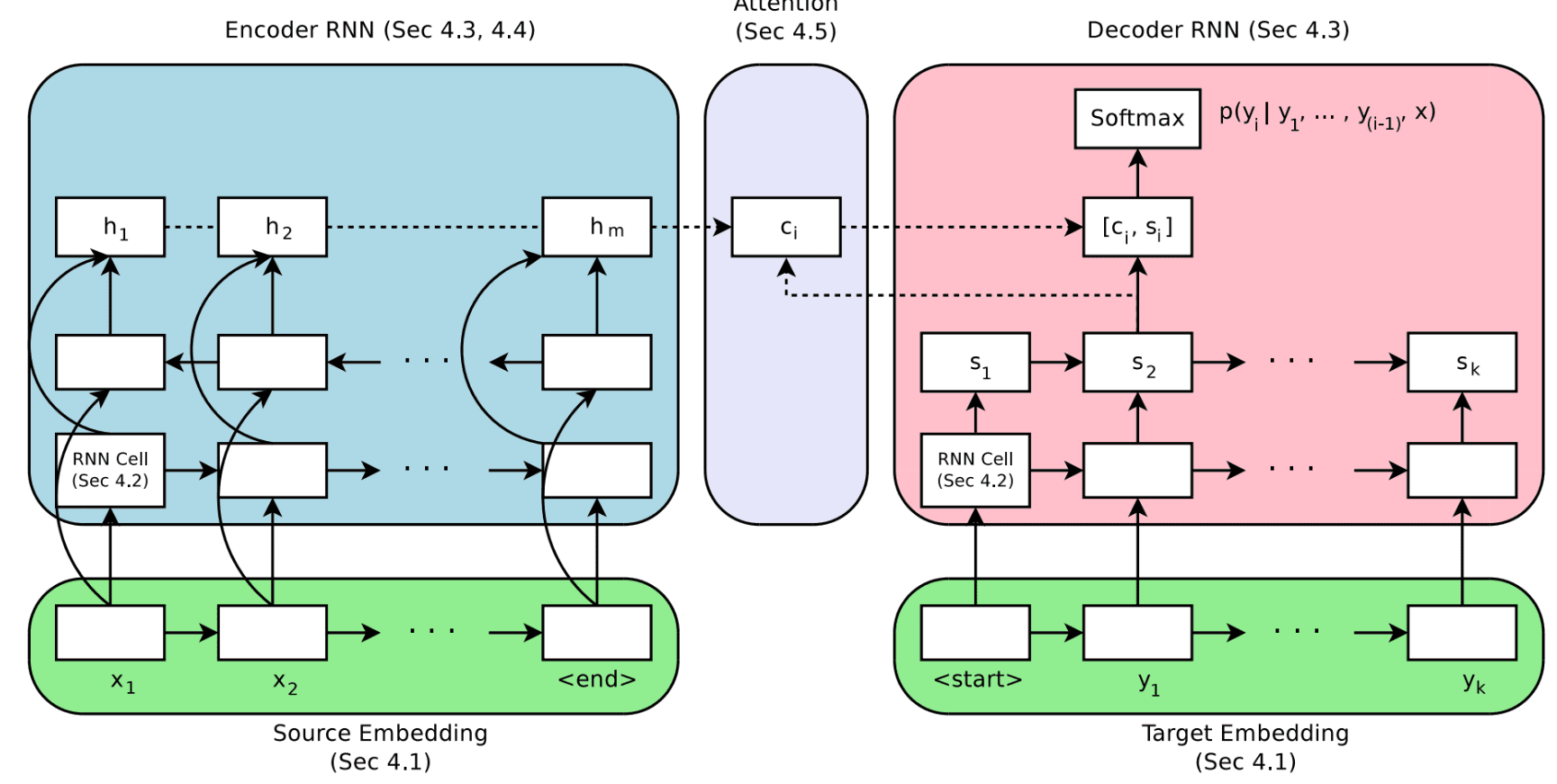
- Encoder: The encoder takes an input sequence, such as a sentence in a source language, and converts it into a fixed-length vector representation. This vector representation, often called the "context" or "thought vector," captures the essential information from the input sequence. The encoder is typically built using recurrent neural networks (RNNs), long short-term memory (LSTM) networks, or transformer-based architectures like the attention mechanism in the Transformer model.
During the encoding process, the encoder reads the input sequence step-by-step and maintains an internal hidden state that captures the contextual information at each time step. After processing the entire input sequence, the encoder produces a final representation that encodes all the relevant information from the input.
- Decoder: The decoder takes the context vector generated by the encoder and uses it to produce the output sequence. For tasks like machine translation or text summarization, the output sequence is typically a translation or summary of the input sequence. The decoder is also constructed using RNNs, LSTMs, or transformers, similar to the encoder.
The decoder operates in a step-by-step manner as well. It initializes its hidden state using the context vector and then generates the output sequence one element at a time. At each time step, the decoder takes into account the previously generated elements of the output sequence and its internal state to produce the next element. This process continues until the end-of-sequence token is generated, indicating that the output sequence is complete.
Training the Encoder-Decoder Model: During training, the encoder-decoder model is given pairs of input and target sequences. The encoder takes the input sequence and produces the context vector, while the decoder uses the context vector to generate the target sequence. The model is trained to minimize the discrepancy between the generated sequence and the actual target sequence, usually measured using a loss function such as cross-entropy.
Encoder-decoder models are a type of neural network architecture that is commonly used in natural language processing (NLP) tasks such as machine translation, text summarization, and question answering. These models consist of two main components: an encoder and a decoder.
The encoder takes an input sequence of text and transforms it into a fixed-length vector representation. This vector representation captures the essential information from the input sequence, and it is then passed to the decoder.
The decoder takes the vector representation from the encoder and generates an output sequence of text. The decoder is typically a recurrent neural network (RNN), which means that it can process the input sequence one token at a time. The decoder generates the output sequence by predicting the next token in the sequence, based on the current token and the vector representation from the encoder.
Enroll Now
- Python Programming
- Machine Learning