Word embedding
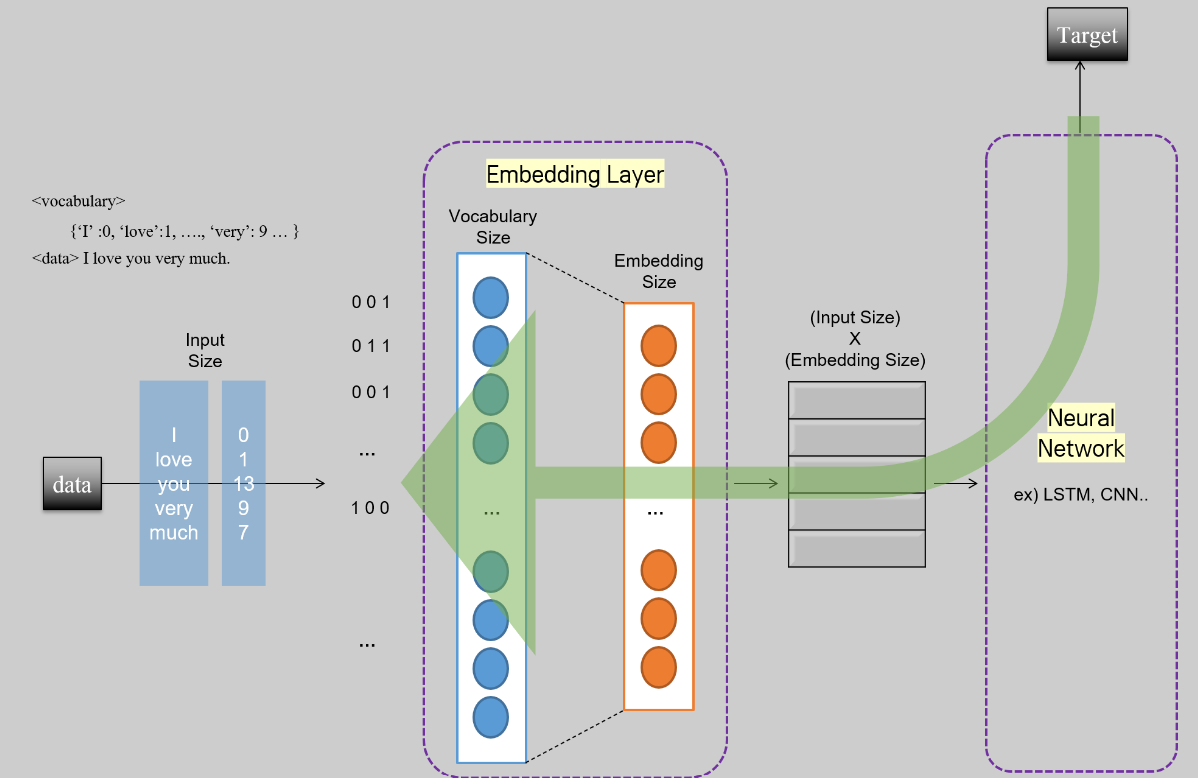
Word embedding is a technique in natural language processing (NLP) that represents words as dense, low-dimensional vectors in a continuous vector space. These word embeddings capture semantic relationships and contextual information about words, allowing NLP models to better understand the meaning and similarity between words.
The traditional representation of words in NLP was based on one-hot encoding, where each word in a vocabulary was represented as a sparse binary vector with a 1 at the position corresponding to the word's index and zeros everywhere else. However, one-hot encoding is highly inefficient as it results in high-dimensional and sparse representations for large vocabularies.
Word embeddings address this issue by mapping words to continuous vectors in a dense vector space where similar words have similar vector representations. Word embeddings are typically learned from large amounts of text data using unsupervised learning techniques. The process of learning word embeddings involves training a neural network (e.g., Word2Vec, GloVe, FastText) to predict the context of a word given its surrounding words or vice versa.
There are several popular methods for learning word embeddings:
-
Word2Vec: Developed by Tomas Mikolov et al., Word2Vec is a shallow neural network that learns word embeddings by predicting the probability of a word given its context (CBOW - Continuous Bag of Words) or predicting the context given a word (Skip-gram). The learned embeddings are effective at capturing semantic relationships between words.
-
GloVe (Global Vectors for Word Representation): Developed by Pennington et al., GloVe uses co-occurrence statistics of words in large text corpora to learn word embeddings. It combines the global statistics of word co-occurrence with local context window information.
-
FastText: Developed by Facebook AI Research (FAIR), FastText extends Word2Vec by representing words as bags of character n-grams. This enables the model to handle out-of-vocabulary words and morphologically related words better.
Word embeddings have numerous applications in NLP, including:
- Improving the performance of various NLP tasks like text classification, sentiment analysis, and named entity recognition.
- Finding similar words and measuring word similarity using vector operations like cosine similarity.
- Providing useful input representations for downstream tasks in deep learning models.
Pre-trained word embeddings, such as Word2Vec, GloVe, and FastText embeddings, are often used as the starting point for many NLP tasks. These pre-trained embeddings can be fine-tuned on specific tasks or used as fixed embeddings in downstream models, saving computation time and resources.
Enroll Now
- Python Programming
- Machine Learning