Part-of-speech (POS) tagging
Part-of-speech (POS) tagging is a fundamental task in natural language processing (NLP) that involves assigning a specific grammatical category or part of speech to each word in a text. The goal of POS tagging is to analyze and understand the structure of a sentence, which can be helpful in various NLP applications such as machine translation, text summarization, sentiment analysis, and more. POS tagging helps computers understand the grammatical and syntactical relationships between words in a sentence.
Some key points about POS tagging:
-
Part of Speech: Parts of speech are linguistic categories that classify words based on their syntactic and semantic functions within a sentence. Common POS categories include nouns, verbs, adjectives, adverbs, pronouns, prepositions, conjunctions, and interjections.
-
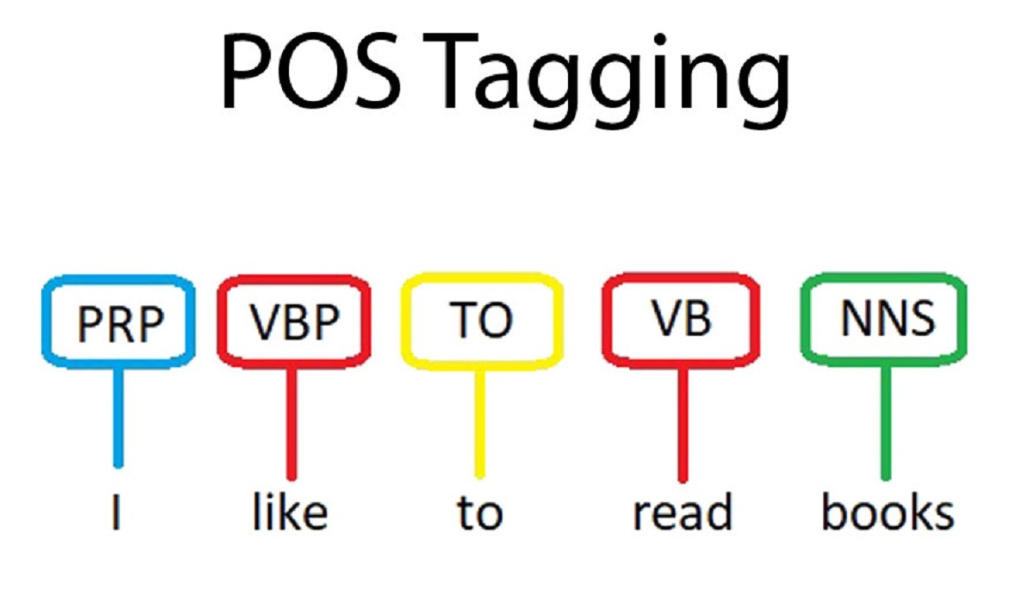
Tagging Process: POS tagging involves processing a text and assigning the appropriate POS tag to each word. For example, in the sentence "The cat sat on the mat," the POS tags might be: "The (Article) cat (Noun) sat (Verb) on (Preposition) the (Article) mat (Noun)."
-
POS Tag Sets: There are different POS tag sets and standards, depending on the language and specific requirements of the task. Common tag sets include the Penn Treebank POS tags for English and the Universal POS tags for cross-lingual applications.
-
Methods: POS tagging can be done using various methods, including rule-based approaches, statistical models, and deep learning techniques. Some popular approaches include Hidden Markov Models (HMMs), Maximum Entropy models, Conditional Random Fields (CRFs), and more recently, recurrent neural networks (RNNs) and transformer-based models like BERT.
-
Training Data: To train a POS tagger, a large corpus of text is required with manually annotated POS tags. Machine learning algorithms learn from these tagged examples to predict POS tags for unseen text.
-
Ambiguity: POS tagging can be challenging because many words have multiple possible parts of speech depending on the context. For example, "book" can be a noun (e.g., "I read a book") or a verb (e.g., "I will book a flight").
-
Applications: POS tagging is a crucial preprocessing step in various NLP tasks, including machine translation, information retrieval, sentiment analysis, and more. It helps improve the accuracy of downstream NLP models and applications.
-
Challenges: POS tagging can be challenging for languages with rich inflectional morphology and for handling out-of-vocabulary words. It also requires handling idiomatic expressions and context-dependent word senses.
In summary, POS tagging is a vital component of natural language processing that helps computers understand the grammatical structure of text. It plays a crucial role in enabling NLP applications to process and analyze human language effectively.
Enroll Now
- Python Programming
- Machine Learning