Decision Tree Algorithm
A Decision Tree is a supervised machine learning algorithm used for both classification and regression tasks.
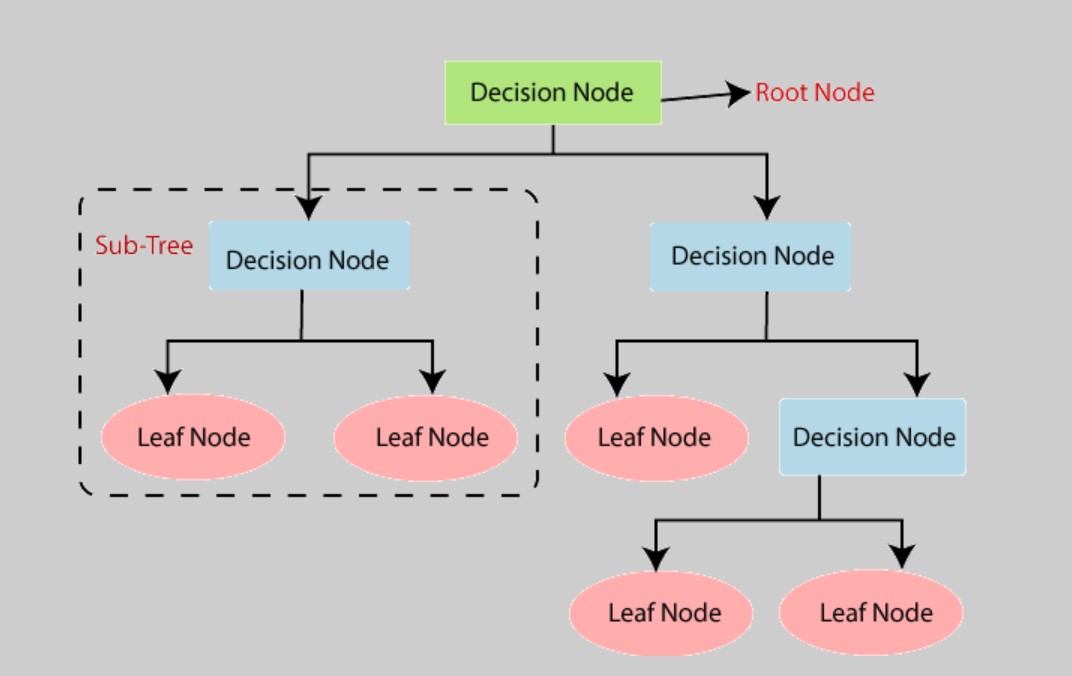
It is a versatile and interpretable model that can be visualized as a tree-like structure, where each internal node represents a feature or attribute, each branch represents a decision or rule based on that feature, and each leaf node represents the outcome or class label.
The key components and concepts associated with the Decision Tree algorithm:
-
Tree Structure:
- The Decision Tree consists of nodes, including the root node (topmost node), internal nodes, and leaf nodes.
- The root node represents the entire dataset.
- Internal nodes represent decisions or tests based on feature values.
- Leaf nodes represent class labels (in classification) or predicted values (in regression).
-
Decision Rules:
- At each internal node, the algorithm selects a feature and a threshold value to split the data into two or more subsets.
- These splits are based on the feature values and aim to maximize the separation between classes (in classification) or minimize the variance (in regression).
-
Entropy and Information Gain (in Classification):
- Decision Trees for classification often use measures like entropy and information gain to decide which feature to split on.
- Entropy measures the impurity or disorder of a dataset. Information gain quantifies how much the entropy decreases after a split. Features with higher information gain are chosen for splits.
-
Gini Impurity (in Classification):
- Another criterion for measuring impurity in classification trees is Gini impurity. It represents the probability of misclassifying a randomly chosen element.
- Like information gain, Decision Trees can also use Gini impurity to evaluate splits, and the feature with lower Gini impurity is chosen.
-
Regression Trees:
- In regression tasks, Decision Trees aim to minimize the variance of the target variable within each leaf node.
- The split criterion in regression trees can be based on minimizing the mean squared error (MSE) or other measures of variance.
-
Pruning:
- Decision Trees have a tendency to overfit the training data by creating deep, complex trees. Pruning is a technique used to reduce the tree's size by removing branches that do not significantly improve predictive performance.
-
Handling Categorical Features:
- Decision Trees can handle both numerical and categorical features. For categorical features, the algorithm may use techniques like one-hot encoding or binary encoding.
-
Interpretability:
- One of the significant advantages of Decision Trees is their interpretability. It's easy to understand the decision logic by inspecting the tree structure.
-
Ensemble Methods:
- Decision Trees are often used as building blocks for ensemble methods like Random Forests and Gradient Boosting, which combine multiple trees to improve predictive performance.
-
Handling Missing Values:
- Decision Trees can handle missing values by finding the best split by considering only available features.
-
Scalability:
- While Decision Trees are easy to understand and interpret, they can be prone to overfitting on small datasets. Ensuring good generalization often requires ensemble methods or other techniques.
Decision Trees are widely used in various domains due to their simplicity and interpretability.
However, they may not perform as well as more complex models on certain tasks, and they can be sensitive to small variations in the data.
Therefore, they are often part of more advanced machine learning solutions, such as ensemble models or used in combination with feature engineering and preprocessing techniques.
Enroll Now
- Python Programming
- Machine Learning