Random Forest Algorithm
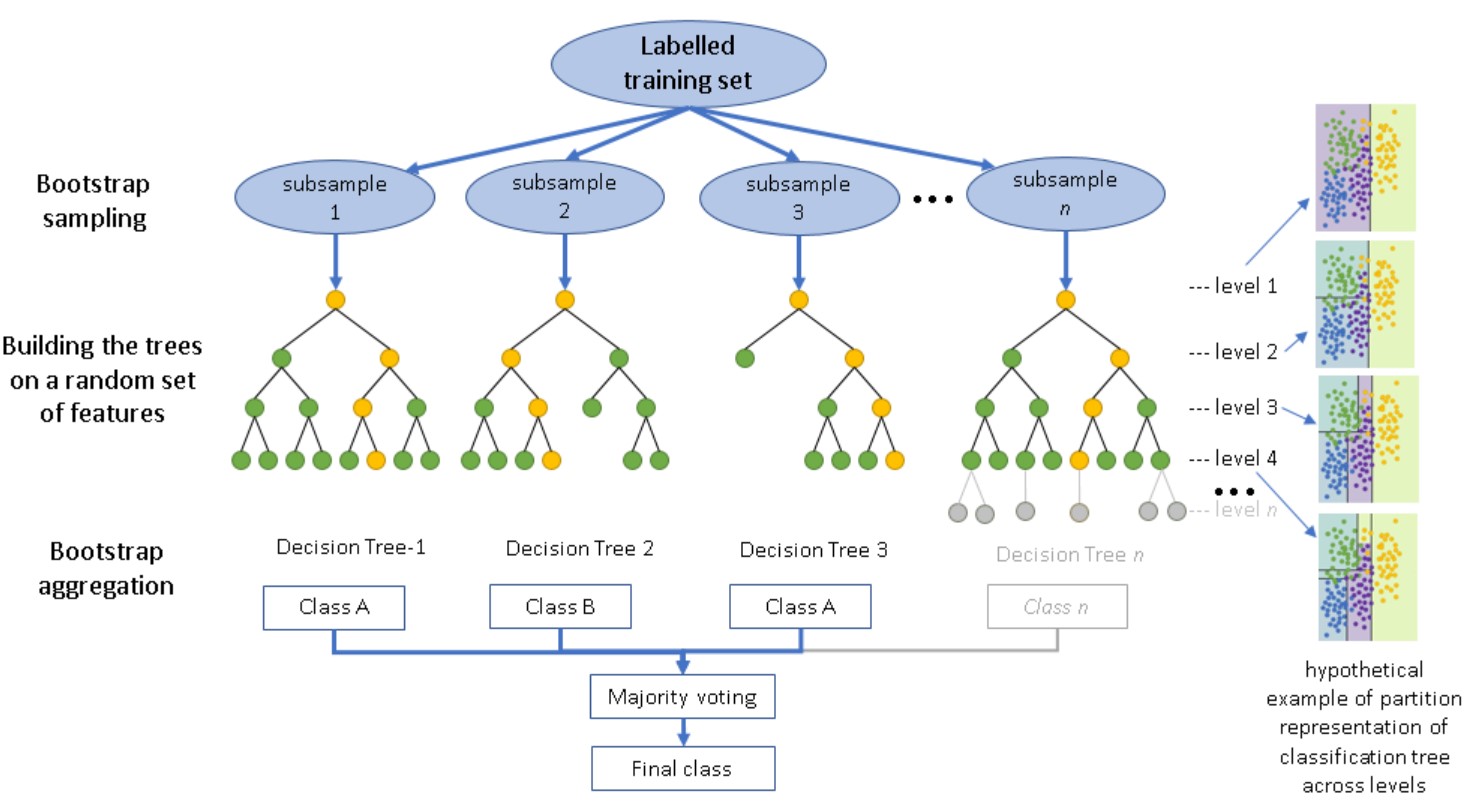
Random Forest is a popular ensemble learning algorithm used in machine learning for both classification and regression tasks.
It operates by constructing a multitude of decision trees during training and outputs the mode of the classes (classification) or the average prediction (regression) of the individual trees.
How Random Forest works and its key features:
-
Decision Trees: Random Forest is based on the concept of decision trees. Decision trees are simple models that recursively partition the feature space into regions, making decisions based on feature values at each node.
-
Ensemble Learning: Random Forest belongs to the ensemble learning methods, which combine multiple individual models to produce a more robust and accurate prediction. In this case, the individual models are decision trees.
-
Random Feature Selection: During the construction of each decision tree in the forest, a random subset of features is selected at each node to determine the best split. This random feature selection helps in decorrelating the trees, reducing overfitting, and improving the robustness of the model.
-
Bootstrap Aggregation (Bagging): Random Forest employs bootstrap aggregation, also known as bagging, to create diverse training datasets for each tree. This involves randomly sampling the training data with replacement to create multiple subsets of the data for training each tree.
-
Voting or Averaging: For classification tasks, Random Forest combines the predictions of individual trees by taking a majority vote among the trees. For regression tasks, the predictions are averaged across all the trees.
-
Hyperparameters: Random Forest has several hyperparameters that can be tuned to optimize its performance, such as the number of trees in the forest, the maximum depth of the trees, the number of features considered for each split, and the minimum number of samples required to split a node.
-
Feature Importance: Random Forest can provide insights into feature importance, which indicates the relative importance of each feature in predicting the target variable. This is calculated based on how much the accuracy of the model decreases when a particular feature is randomly permuted.
-
Robustness: Random Forest is robust to noisy data and outliers due to the averaging effect of multiple trees. It also tends to perform well on large datasets with high dimensionality.
Benefits of Random Forests:
- Accuracy and Robustness: By combining multiple learners, random forests generally achieve higher accuracy and are less prone to overfitting the training data compared to a single decision tree.
- Can Handle Different Data Types: They can work effectively with both categorical and continuous data.
- Interpretability: While the inner workings of each tree might be complex, the overall prediction process remains relatively interpretable by looking at which features were most important across the trees.
Drawbacks to Consider:
- Can be Computationally Expensive: Training a random forest with many trees can be computationally demanding.
- Black Box Tendencies: Though more interpretable than some algorithms, understanding exactly why a forest makes a particular prediction can still be challenging.
Random Forest is widely used in various domains such as finance, healthcare, and bioinformatics due to its simplicity, scalability, and ability to handle complex datasets.
However, it may not perform as well as more sophisticated models in certain scenarios, such as with highly imbalanced datasets or when dealing with sequential data.
Enroll Now
- Python Programming
- Machine Learning