K-Means Algorithm
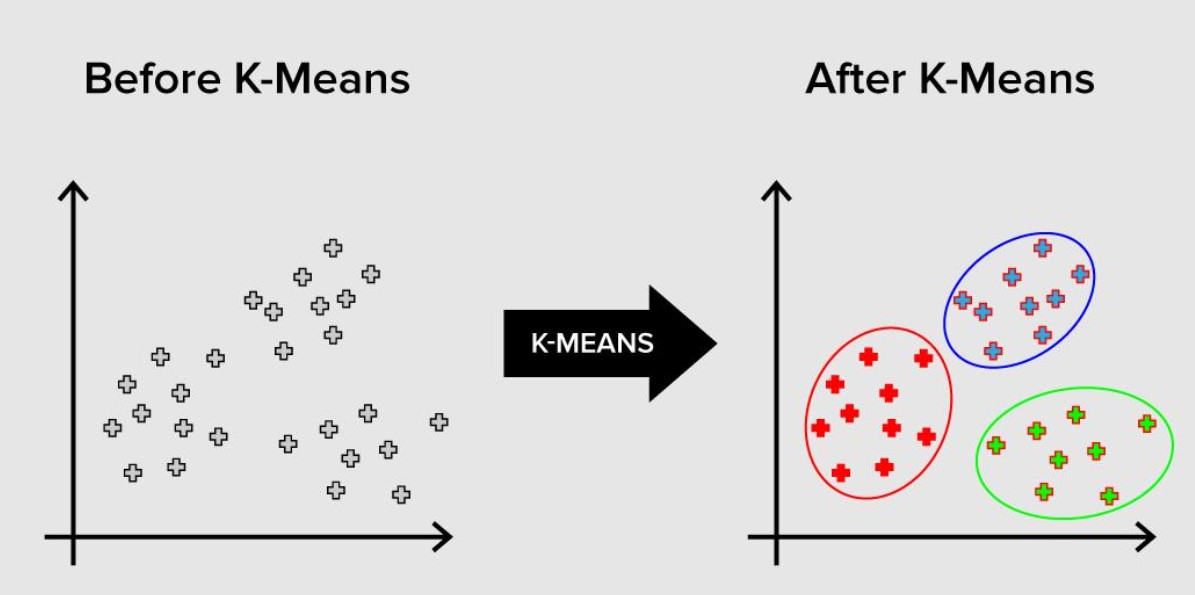
The k-means algorithm is a popular unsupervised learning technique used in machine learning. It is used for clustering a set of data points into groups or clusters based on their similarity.
The algorithm works as follows: Choose the number of clusters you want to create, denoted by K. Initialize K cluster centroids randomly.
Assign each data point to the nearest centroid. Update the centroids based on the mean of the data points assigned to each cluster.
Repeat steps 3 and 4 until the centroids no longer move significantly.
The objective of the algorithm is to minimize the sum of the squared distances between each data point and its assigned centroid.
This is known as the within-cluster sum of squares (WCSS).
K-means can be used for a variety of applications, such as customer segmentation, image segmentation, and anomaly detection.
However, it is sensitive to the initial placement of the centroids and may converge to a suboptimal solution if the data has a complex structure or if the clusters have different sizes or densities.
Enroll Now
- Python Programming
- Machine Learning