Reinforcement Learning (RL)
Reinforcement Learning (RL) is a type of machine learning paradigm that focuses on training agents to make sequences of decisions in an environment to maximize cumulative rewards.
Unlike supervised learning, where a model is trained on labeled data, or unsupervised learning, where patterns are extracted from unlabeled data, RL deals with decision-making and learning from interaction.
Some fundamental components and concepts of reinforcement learning:
-
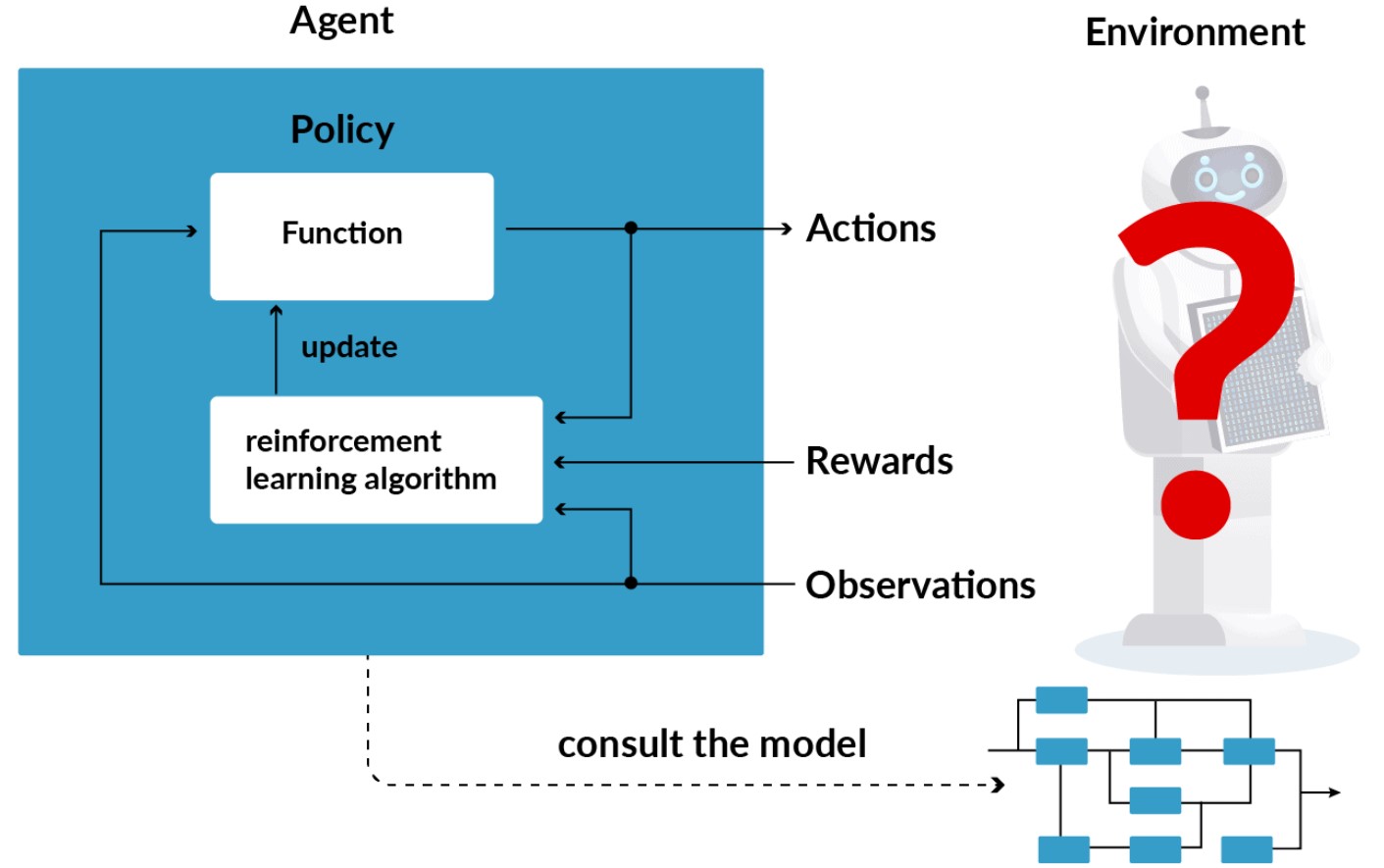
Agent: The agent is the learner or decision-maker that interacts with the environment. It takes actions based on the information it receives from the environment and aims to maximize its long-term reward.
-
Environment: The environment represents the external system with which the agent interacts. It includes everything the agent cannot control but can perceive, such as the physical world, a game environment, or a simulated domain.
-
State (s): A state is a representation of the environment's current situation. It captures relevant information that the agent uses to make decisions. States can be discrete or continuous.
-
Action (a): Actions are the choices that the agent can make to influence the environment. The set of all possible actions is called the action space.
-
Policy (π): A policy is a strategy that defines the agent's behavior. It maps states to actions, determining what action the agent should take in each state. Policies can be deterministic or stochastic.
-
Reward (r): At each time step, the agent receives a numerical reward signal from the environment. The reward quantifies the immediate benefit or cost of taking a particular action in a specific state. The agent's objective is to maximize the cumulative reward over time.
-
Value Function (V): The value function estimates the expected cumulative reward the agent can achieve starting from a given state and following a particular policy. It helps the agent assess the desirability of states.
-
Q-Value Function (Q): The Q-value function estimates the expected cumulative reward the agent can achieve by taking a specific action in a given state and following a particular policy. It helps the agent assess the desirability of actions.
-
Exploration vs. Exploitation: The agent faces the exploration-exploitation dilemma. It must explore different actions to discover the optimal strategy while exploiting known information to maximize short-term rewards.
-
Markov Decision Process (MDP): MDP is a formal framework that models the RL problem as a sequence of states, actions, and rewards. It assumes the Markov property, meaning that the future state depends only on the current state and action.
-
Episodes and Trajectories: RL problems are often framed as episodic or continuing tasks. An episode is a sequence of interactions from an initial state to a terminal state. Trajectories represent individual sequences of states, actions, and rewards within an episode.
-
Discount Factor (γ): The discount factor, often denoted as γ (gamma), determines the importance of future rewards relative to immediate rewards. It influences the agent's preference for short-term or long-term gains.
Reinforcement learning algorithms, such as Q-learning, SARSA, and deep reinforcement learning methods like Deep Q-Networks (DQN) and Proximal Policy Optimization (PPO), are used to train agents to learn optimal policies in various environments.
RL has applications in robotics, game playing, autonomous vehicles, recommendation systems, and many other fields where sequential decision-making is required.
Enroll Now
- Python Programming
- Machine Learning