Support Vector Machine
Support Vector Machine (SVM) is a supervised learning algorithm used for classification and regression tasks.
It's particularly effective in high-dimensional spaces and when the number of features exceeds the number of samples. SVM works by finding the hyperplane that best separates the data into different classes in feature space.
How SVM works and its key features:
-
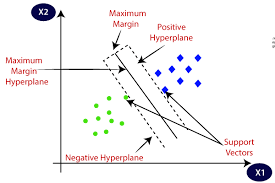
Linear Separability: SVM aims to find the hyperplane that best separates the data points of different classes in feature space. If the classes are linearly separable, SVM finds the hyperplane that maximizes the margin, which is the distance between the hyperplane and the nearest data points (support vectors) from each class.
-
Non-linear Separability: In cases where the data is not linearly separable, SVM can still be applied by using a kernel trick. The kernel function maps the original feature space into a higher-dimensional space where the data might be linearly separable. Common kernel functions include linear, polynomial, radial basis function (RBF), and sigmoid kernels.
-
Margin Maximization: SVM aims to maximize the margin around the separating hyperplane. A larger margin generally indicates a more robust and generalized model that is less prone to overfitting.
-
Support Vectors: Support vectors are the data points that lie closest to the hyperplane and directly influence its position. These are the critical data points that determine the margin and the decision boundary.
-
Soft Margin SVM: In cases where the data is not perfectly separable, SVM can use a soft margin approach. The soft margin allows for some misclassification errors to be made to achieve a better overall fit. The trade-off between margin maximization and error minimization is controlled by a regularization parameter (C).
-
Kernel Trick: The kernel trick allows SVM to implicitly map the input data into high-dimensional feature spaces without actually computing the transformed feature vectors explicitly. This makes SVM computationally efficient even in high-dimensional or infinite-dimensional spaces.
-
Regularization: SVM incorporates regularization through the parameter C, which controls the trade-off between maximizing the margin and minimizing the classification error. A smaller value of C encourages a larger margin but may lead to more misclassifications, while a larger value of C allows for fewer misclassifications but may result in a smaller margin.
-
Binary Classification and Multi-class Classification: SVM is inherently a binary classifier. However, techniques such as one-vs-one or one-vs-all can be used to extend SVM to handle multi-class classification tasks.
Advantages of Support Vector Machines:
- Effective for high-dimensional data: SVMs perform well even with many features, making them suitable for complex datasets.
- Good generalization: The focus on maximizing the margin leads to models that often generalize well to unseen data.
- Memory efficiency: During training, SVMs only focus on the support vectors, reducing memory requirements compared to algorithms that train on all data points.
Limitations to Consider:
- Computational cost: Training SVMs can be computationally expensive, especially for large datasets.
- Not ideal for very high dimensionality: While SVMs can handle high dimensions, extreme cases can lead to computational challenges.
- Tuning hyperparameters: The effectiveness of SVMs can be sensitive to the choice of hyperparameters (kernel function, regularization parameters), requiring careful tuning.
SVM has been successfully applied in various domains, including text categorization, image classification, bioinformatics, and financial forecasting.
Its ability to handle high-dimensional data, flexibility in choosing different kernel functions, and robustness to overfitting make it a popular choice in many machine learning applications.
However, SVMs may become computationally expensive and memory-intensive for very large datasets, and they may not perform as well when dealing with noisy data or datasets with a large number of classes.
Enroll Now
- Python Programming
- Machine Learning