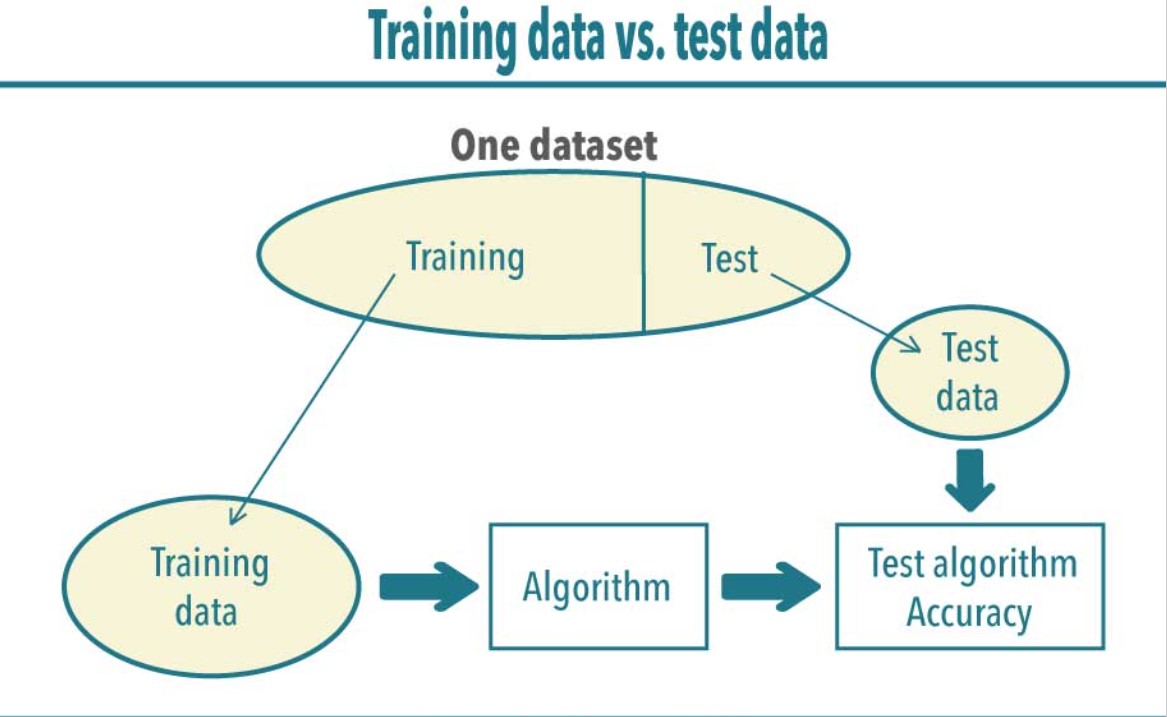
Training and Testing Data Sets
In machine learning, dividing data into training and testing sets is a fundamental practice to assess the performance of a model.
Detailed explanation of training and testing data:
-
Training Data:
- Training data is the portion of your dataset used to train your machine learning model. It contains examples of input data along with their corresponding target values (also known as labels or outcomes).
- The primary goal during the training phase is for the model to learn patterns, relationships, and representations within the data. It optimizes its internal parameters to make accurate predictions or classifications based on the input features.
- Typically, the training data constitutes a significant portion of the entire dataset, often around 70-80% of the data, depending on the specific problem and dataset size.
-
Testing Data:
- Testing data, sometimes referred to as validation data or a holdout set, is a separate portion of the dataset that is not used during the model training phase.
- It contains only input features, and its corresponding target values are kept hidden from the model during testing.
- The testing data is used to assess the model's performance and to evaluate how well it generalizes to new, unseen examples.
- The testing data usually comprises the remaining portion of the dataset, approximately 20-30%.
The process of training and testing in machine learning typically follows these steps:
-
Training Phase:
- The model is trained using the training data. During training, the model learns to recognize patterns, make predictions, or classify data based on the provided features and target labels.
- The model's internal parameters (weights and biases in the case of neural networks, for example) are adjusted through optimization algorithms like gradient descent to minimize prediction errors.
-
Testing (Validation) Phase:
- After the model has been trained, it is evaluated using the testing data.
- The model makes predictions or classifications on the testing data based on what it learned during training.
- The true target values in the testing data are then compared to the model's predictions to assess its performance.
-
Performance Evaluation:
- Various evaluation metrics are used to measure how well the model performs on the testing data. Common metrics include accuracy, precision, recall, F1-score, and mean squared error (for regression problems), among others.
- These metrics provide insights into the model's ability to generalize and make accurate predictions on new, unseen data.
-
Iterative Process:
- Depending on the evaluation results, you may need to fine-tune your model, adjust hyperparameters, or choose a different algorithm to improve its performance.
- This process of training, testing, and refining the model is often iterative and continues until satisfactory results are achieved.
The separation of data into training and testing sets is crucial for assessing a machine learning model's ability to generalize to new, unseen data and to prevent issues like overfitting (where the model performs well on the training data but poorly on new data) or underfitting (where the model fails to capture the underlying patterns in the data).
Cross-validation techniques can also be used to obtain a more robust evaluation of the model's performance.
Enroll Now
- Python Programming
- Machine Learning